
A Comprehensive Guide to Choosing the Right Data Storage Solution for Your Business
November 15, 2024
Lovneet Singh
Sr. Architect @ RadiansysIntroduction
Data management has become crucial for businesses looking to leverage data for competitive advantage. The choice between a Data Lake and a Data Warehouse as a data storage solution often depends on the type of data a business handles, its data management goals, and the analytical approaches it wants to employ. This article delves into the core differences between Data Lakes and Data Warehouse, their benefits, limitations, and when businesses should consider each option.
Understanding Data Lakes and Data Warehouses: A Technical Deep Dive
Data Lakes
Data lakes are vast, flexible storage repositories that hold raw, unstructured, and semi-structured data at scale, supporting diverse data types such as logs, media, and sensor data. Designed for exploratory analysis and machine learning, Data Lakes enable rapid ingestion without predefined schemas, making them ideal for handling massive volumes of varied data.
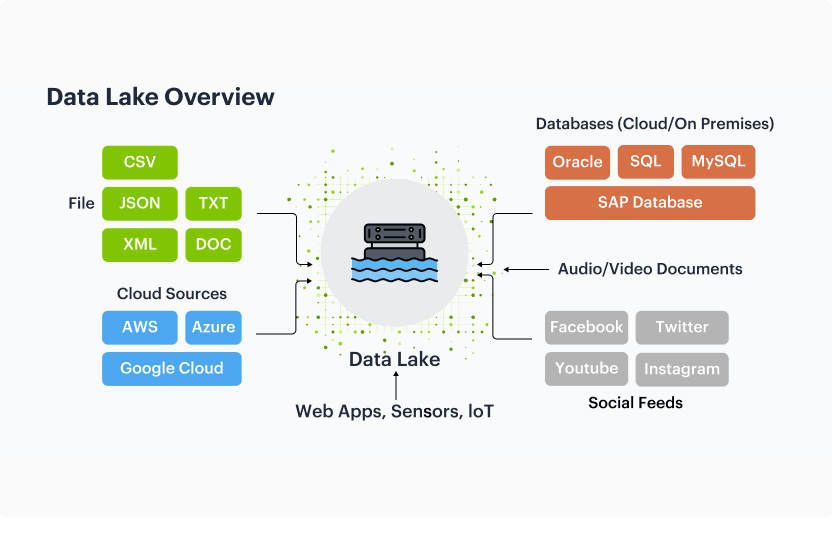
Features
Storage Flexibility
Data lakes can store raw, structured, semi-structured, and unstructured data in various formats, such as Parquet, ORC, Avro, JSON, and even media files like audio and video. They are commonly built on distributed storage systems, such as Amazon S3, Azure Data Lake Storage, or Hadoop Distributed File System (HDFS), allowing them to scale out as data volumes grow.
Data Ingestion
Data Lakes support ingestion through batch processing, real-time streaming, or micro-batching using technologies like Apache Kafka, Apache NiFi, and AWS Kinesis.
Data Processing and Analysis
Leveraging tools like Apache Spark, Hive, and Presto, Data Lakes enable data scientists to perform large-scale data processing and run exploratory data analysis, machine learning, and ETL processes within the lake.
Data Warehouse
Data Warehouse are structured storage solutions optimized for storing processed, high-quality data, primarily used for business intelligence and reporting. They enforce a strict schema-on-write approach, ensuring data consistency and fast querying, ideal for complex analyses and real-time insights.
Features
Optimized for Analytics
Data Warehouse use columnar storage formats (e.g., Snowflake’s storage format, Redshift’s optimized columnar storage) that are optimized for aggregations and complex joins, making them ideal for reporting and business intelligence.
ETL/ELT Pipelines
Data Warehouse require structured data and often use ETL or ELT (Extract, Load, Transform) processes to clean and organize data before loading it into the database. This is typically done using tools like Apache Airflow, Talend, and dbt (data build tool).
Query and Analytics Tools
SQL-based analytics platforms, such as Looker, Tableau, and Power BI, can directly connect to Data Warehouse for rapid querying, providing the performance needed for daily reports and dashboards in BI environments.
Technical Comparison: Architecture and Storage
Data Lakes and Data Warehouse differ significantly in their architectural design and storage methods, each optimized for specific data handling and processing requirements. Understanding these core differences can help businesses choose a solution that aligns with their data volume, structure, and analytical needs.
Characteristics
Data
Schema
Price/Performance
Data Quality
Users
Analytics
Data Warehouse
Relational from transactional systems, operational databases, and line of business applications.
Designed prior to the DW implementation (schema-on-write).
Fastest query results using higher cost storage.
Highly curated data that serves as the central version of the truth.
Business analysts.
Batch reporting, BI, and visualizations.
Data Lake
Non-relational and relational from IoT devices, websites, mobile apps, social media, and corporate applications.
Written at the time of analysis (schema-on-read).
Query results getting faster using low-cost storage.
Any data that may or may not be curated (i.e., raw data).
Data developers, and Business analysts (using curated data).
Machine Learning, Predictive analytics, data discovery, and profiling.
Schema-on-Write vs. Schema-on-Read
- Data Warehouse: Schema-on-write requires strict schema definitions before data is written, ensuring clean, high-quality data, which is optimized for SQL queries and relational joins. This approach uses relational databases (like Snowflake, Redshift, or BigQuery) to enforce integrity at ingestion.
- Data Lake: Schema-on-read means data is stored as-is, with the schema applied only when read for analysis. Technologies like Apache Hive, Presto, and SparkSQL allow for late binding of schema, making Data Lakes highly adaptable and useful for diverse data sources.
Data Partitioning and Indexing
- Data Warehouse: Indexes and partitions in Data Warehouse are optimized for fast retrieval and complex aggregations. For example, Amazon Redshift uses sort and distribution keys, while Snowflake leverages micro-partitioning to optimize query performance.
- Data Lake: Partitioning in Data Lakes is more flexible and typically directory-based (e.g., by date, type, or event), with data catalogs like AWS Glue or Apache Hive Metastore managing data locations. However, because raw data is unindexed, querying in Data Lakes may require more processing.
Storage Solutions and Compression
- Data Lake Storage: Object storage like Amazon S3, Azure Blob Storage, and Google Cloud Storage provides low-cost, high-durability solutions. Data lakes often store data in compressed formats (like Parquet, ORC, or Avro) to reduce storage and improve read efficiency.
- Data Warehouse Storage: Dedicated warehouse use optimized compression techniques (e.g., BigQuery’s Capacitor format, Redshift’s columnar encoding) for structured data, enhancing performance and reducing costs.
Opportunities and Challenges
Choosing between Data Lakes and Data Warehouse involves understanding each solution’s unique opportunities for maximizing data potential and the challenges they may introduce. Here’s a closer look at how each option supports specific business and technical needs, along with factors to consider for optimal implementation.
Data Lake Opportunities
- Scalability and Flexibility: Data lakes provide exceptional scalability, accommodating petabyte-scale storage for structured, semi-structured, and unstructured data.
- Cost Efficiency: Utilizing cloud-based storage like Amazon S3 or Azure Data Lake, data lakes follow a pay-as-you-go model. This approach is highly cost-effective for storing large volumes of infrequently accessed or "cold" data.
- Integration with Machine Learning Tools: Data lakes integrate seamlessly with popular machine learning frameworks (e.g., TensorFlow, PyTorch) and distributed processing tools like Apache Spark, providing data scientists with a powerful foundation for high-throughput analysis and AI applications.
Data Lake Challenges
- Risk of Data Swamps: Without strict governance and metadata management, data lakes can turn into "data swamps," making data retrieval difficult and obscuring valuable insights.
- Performance Limitations: Data lakes store raw, unindexed data, which can result in slower query performance compared to structured systems, especially for complex queries or aggregations.
- Security and Compliance Complexities: Distributed storage necessitates advanced configurations for IAM policies, encryption, and compliance. These requirements can be more complex than those in traditional data warehouses.
Data Warehouse Opportunities
- High Performance for BI and Reporting: Optimized for structured data and complex queries, Data Warehouse provide real-time insights, making them ideal for business intelligence, operational reporting, and fast data retrieval.
- Enhanced Data Governance and Compliance: Data Warehouse offer robust data governance with fine-grained access control, role-based permissions, and compliance with regulatory standards such as GDPR and HIPAA, critical for regulated industries.
- Data Consistency and Quality: Schema enforcement and structured ETL processes ensure high data quality and consistency, which are essential for reliable reporting and analytics.
Data Warehouse Challenges
- Higher Storage Costs: Due to the need for structured, high-quality storage, Data Warehouse can be more costly per unit of data than Data Lakes, especially when scaling to larger datasets.
- Limited Flexibility for Diverse Data Types: Primarily supporting structured data, Data Warehouse may struggle to accommodate semi-structured or unstructured data, limiting their use in some big data or machine learning applications.
- Complex ETL Requirements: Establishing ETL pipelines can be resource-intensive and time-consuming, particularly for rapidly changing data sources or businesses requiring quick adaptation.
Use Cases: When to Choose a Data Lake or Data Warehouse
Selecting between a Data Lake and a Data Warehouse depends on the type of data, analytical goals, and specific business needs. Here’s a guide to when each storage solution is most effective, helping businesses make an informed decision based on their unique data requirements.
Use Cases for Data Lakes
- Data Science and AI Applications: With support for diverse, large-scale datasets, Data Lakes are suitable for data science teams working on machine learning, predictive modeling, and natural language processing (NLP).
- Real-Time IoT Data: IoT sensors generate vast amounts of data continuously, and Data Lakes can store this raw, time-series data at scale. Tools like Kinesis or Apache Flink can feed real-time data directly into lakes.
- Historical and Archived Data Storage: For storing long-term historical data, Data Lakes offer a cost-effective option, especially for companies in finance or retail requiring data retention for compliance or trend analysis.
Use Cases for Data Warehouse
- Business Intelligence and Reporting: Data Warehouse serve as the backbone for BI and reporting, enabling companies to run weekly or daily reports on sales, revenue, and KPIs.
- Customer 360 Analytics: With structured customer data, Data Warehouse help businesses analyze behavior, segment customers, and make personalized marketing decisions.
- Regulatory Compliance and Auditing: Industries such as banking, healthcare, and finance require clean, auditable data, which Data Warehouse provide with schema consistency and access control.
Hybrid Approaches and Modern Data Architectures
As data needs evolve, hybrid architectures like the Data Lakehouse offer a blend of Data Lake flexibility and Data Warehouse performance. These modern solutions enable businesses to leverage both structured and unstructured data, supporting advanced analytics and machine learning within a unified platform.
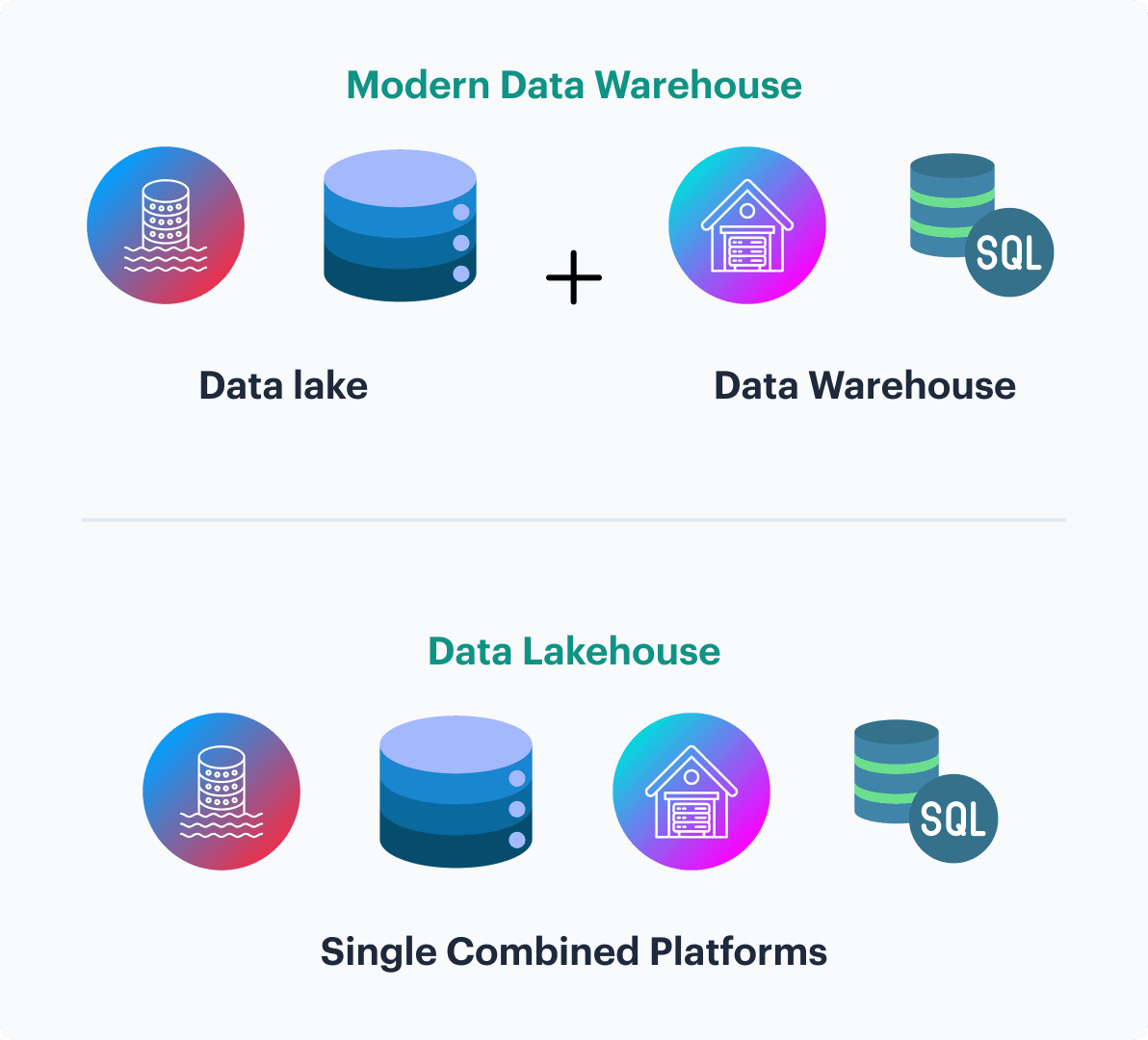
Data Lakehouse
Combines the flexibility of Data Lakes with the performance and structure of Data Warehouse. Tools like Databricks Lakehouse, Snowflake, and Google BigQuery’s BigLake provide single environments for both BI and data science, reducing data silos.
- Unified Data Management: By combining structured and unstructured data, Lakehouse support multiple analytical and machine learning workloads on a single platform.
- Performance Optimizations: Lakehouse architectures enable performance improvements by indexing, caching, and optimizing query engines.
ETL vs. ELT Approaches
- ETL (Extract, Transform, Load): Traditionally used with Data Warehouse, where data is transformed to fit a predefined schema before loading. ETL is efficient for data consistency but requires high upfront planning.
- ELT (Extract, Load, Transform): Suited for Data Lakes, allowing for data to be loaded first in its raw form and transformed as needed. ELT provides greater flexibility for data scientists to experiment but may require more processing power.
Technical and Business Decision Factors
Cost Considerations
- Data Lake Costs: Highly cost-effective for storing large amounts of data with “cold” storage options, such as AWS Glacier. However, processing costs can rise if frequent, complex queries are run.
- Data Warehouse Costs: Due to compute and storage requirements, Data Warehouse incur higher operational costs, but data governance and high performance often justify these for high-frequency analytics.
Performance and Speed
- Data Lakes: Designed for high-throughput, batch processing rather than low-latency querying. Interactive queries require technologies like Apache Presto or Dremio for performance optimization.
- Data Warehouse: Engineered for fast, ad hoc querying with optimized storage engines, indexing, and caching to minimize latency.
Data Governance
- Data Lakes: Require additional tools for governance and metadata management, such as Apache Atlas, AWS Glue, or Azure Purview, for asset tagging and data cataloging.
- Data Warehouse: Have built-in data governance with auditing, access control, and compliance features necessary for industries handling sensitive data.
Future Trends and Evolving Technologies
As data needs evolve, hybrid architectures like the Data Lakehouse offer a blend of Data lake flexibility and Data Warehouse performance. These modern solutions enable businesses to leverage both structured and unstructured data, supporting advanced analytics and machine learning within a unified platform.
Lakehouse Adoption
As enterprises seek unified data solutions, hybrid Data Lakehouse are gaining traction. With advancements in storage (Delta Lake, Iceberg) and compute engines (Databricks, Snowflake), Lakehouse enable businesses to run BI and ML in a single environment.
AI and Machine Learning Integration
Data Lakes and Lakehouse increasingly support machine learning pipelines, leveraging ML libraries and frameworks within these environments to develop predictive analytics solutions.
Cloud Data Management
The cloud has democratized access to scalable storage solutions, and Data Lakes and Warehouse are increasingly hosted on platforms like AWS, Azure, and Google Cloud, offering cross-service integrations and managed security solutions.
Conclusion
For businesses choosing between Data Lakes and Data Warehouse, the decision hinges on data volume, analytical needs, compliance requirements, and budget. Data Lakes offer the flexibility needed for diverse data types and large-scale machine learning. In contrast, Data Warehouse provide the structure and governance essential for high-quality reporting and BI. Modern architectures, such as the Data Lakehouse, aim to bridge the gap, offering solutions that leverage the strengths of both, making data storage decisions more flexible and adaptable to evolving business needs.
Thanks for reading!
Your AI future starts now.
Partner with Radiansys to design, build, and scale AI solutions that create real business value.