
Apache Kafka: Powering Scalable Real-Time Data Streaming and Analytics
December 12, 2024
Lovneet Singh
Sr. Architect @ RadiansysIn the world of modern data-driven applications, Apache Kafka has emerged as the go-to platform for handling real-time data streams. Its robustness, scalability, and fault tolerance make it indispensable for organizations seeking to leverage real-time analytics, event-driven architectures, and large-scale data integration. Kafka's ability to handle high-throughput data with low latency has made it a key component in building scalable, resilient data pipelines.This comprehensive guide delves deep into Kafka's architecture, components, operations, and its significance in shaping the data pipelines of the future, driving innovation across industries.
Apache Kafka is the backbone of modern real-time data streaming and processing. It connects data producers, Kafka itself, and data consumers to create a powerful ecosystem that drives insights and innovation. Here’s a detailed breakdown of Kafka's role in managing data flows.
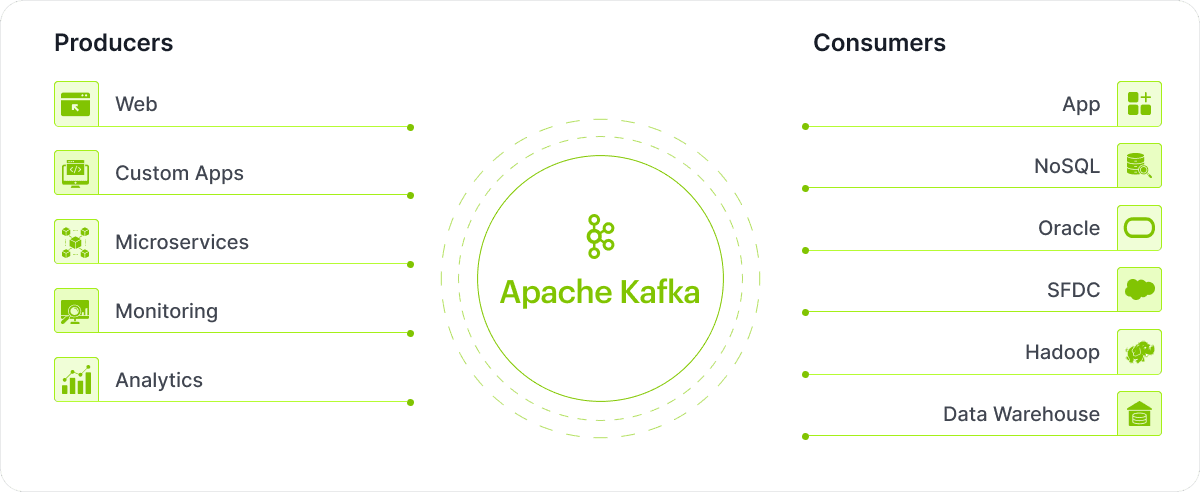
Data producers are the origin of information in the Kafka ecosystem. They feed raw data into Kafka, enabling real-time processing. Examples include
Track user interactions like clicks, page views, and logins in real time.
Operational data from internal tools, such as CRM systems or billing applications.
Share events like "Order Placed" or "Payment Completed" across distributed services.
Stream logs and metrics for real-time analysis of servers and applications.
Deliver data streams to Kafka for creating dashboards and insights.
At the ecosystem's core, Kafka facilitates seamless data streaming, storage, and scalability. It handles high-throughput data streams in real time.
Temporarily or permanently stores data, safeguarding it against system failures.
Streams data to consumers instantly, allowing systems to process and act on information as it arrives.
Partitions data into smaller units for parallel processing, enabling Kafka to handle millions of events every second.
Replicates data across brokers, ensuring availability even if a server goes down.
Facilitates seamless connectivity across systems with Kafka Connect, allowing easy integration with various data sources and sinks to maintain a unified data flow.
Data consumers are the systems that pull and process data from Kafka to generate insights or perform actions. Examples include
Mobile and web apps use real-time Kafka data to deliver notifications and live updates.
Store and query Kafka streams using systems like MySQL, PostgreSQL, or MongoDB.
Partitions data into smaller units for parallel processing, enabling Kafka to handle millions of events every second.
Systems like Hadoop consume Kafka streams for large-scale data processing.
Tools like Tableau and Power BI create live dashboards and reports from Kafka data.
Apache Kafka offers a comprehensive set of features designed to handle real-time, large-scale, and fault-tolerant data streaming. Here’s a breakdown of its standout capabilities:
Kafka's distributed architecture operates as a cluster of brokers, enabling scalability, resilience, and efficient data management.Data is distributed across brokers, allowing dynamic scaling and ensuring fault-tolerant processing of increased workloads.
Kafka is designed to handle millions of messages per second, making it ideal for large-scale applications like log aggregation and real-time analytics.Leveraging sequential disk writes and batch processing, Kafka ensures high throughput without compromising efficiency, perfect for IoT and big data use cases.
Reliability is at the heart of Kafka. It replicates partitions across brokers, ensuring data remains available even if a broker fails.Kafka promotes a follower replica to maintain data availability without manual intervention if a partition leader goes offline.
Kafka ensures data durability by storing messages on disk. Messages can be retained for a defined period or until storage limits are reached, even after consumed.Consumers can replay and reprocess data by revisiting stored messages, making Kafka ideal for debugging and recovering lost data.
Partitioning is a core design feature of Kafka. Topics are divided into partitions, allowing multiple producers and consumers to process data simultaneously.Partitions are distributed across brokers for balanced workloads. Kafka maintains strict ordering within each partition, which is critical for use cases like financial transactions or event sourcing.
Kafka delivers messages with low latency, making it perfect for real-time applications. It powers systems that react instantly to events, such as fraud detection, stock price tracking, or personalized recommendations.Kafka integrates with popular stream processing tools like Apache Flink, Apache Spark, and Kafka Streams.
Kafka provides a flexible publish-subscribe model. Producers publish messages on topics without worrying about the consumers, and consumers fetch messages at their own pace.The pull-based consumption model ensures slower consumers don’t impact the system’s performance.
Kafka offers a robust ecosystem with APIs for producing, consuming, stream processing, and integrating external systems like databases and file systems.Key APIs include Producer, Consumer, Streams, Connect, and Admin, enabling real-time processing, system integration, and resource management.
Kafka supports horizontal scaling through dynamic partitioning, allowing topics to handle increasing workloads efficiently.Brokers can be added or removed without downtime, ensuring seamless adaptation to changing demands and future-proofing for data growth.
Apache Kafka offers extensive configuration options to enhance performance, ensure reliability, and improve scalability. Properly tuning these configurations allows organizations to optimize Kafka for their specific use cases. Below are the key configuration categories with detailed explanations of their parameters:
Broker configurations determine how Kafka brokers handle message storage, networking, and resource management.
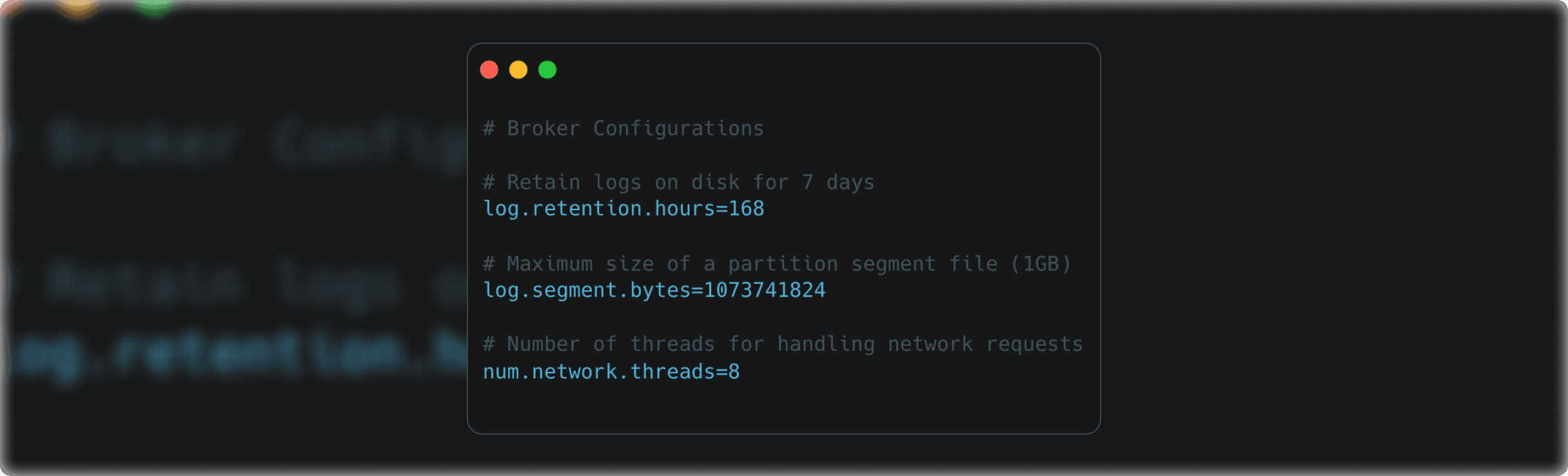
- log.retention.hours: Specifies how long messages are retained on disk.
- log.segment.bytes: Determines the maximum size of a partition segment file before rolling over.
- num.network.threads: Sets the number of threads for handling network requests, impacting concurrency and throughput.
Topic-level configurations control how data is partitioned, replicated, and retained. These settings are key to scalability and fault tolerance
- For an existing topic, update its configurations
- Topic-Specific Configurations

- partitions: : Number of partitions per topic for parallel processing.
- replication.factor: : Number of replicas per partition for fault tolerance.
- cleanup.policy: : Message retention (delete for expiration, compact for deduplication.
Producer configurations impact how messages are sent, acknowledged, and compressed. These settings are crucial for balancing speed, reliability, and network efficiency.
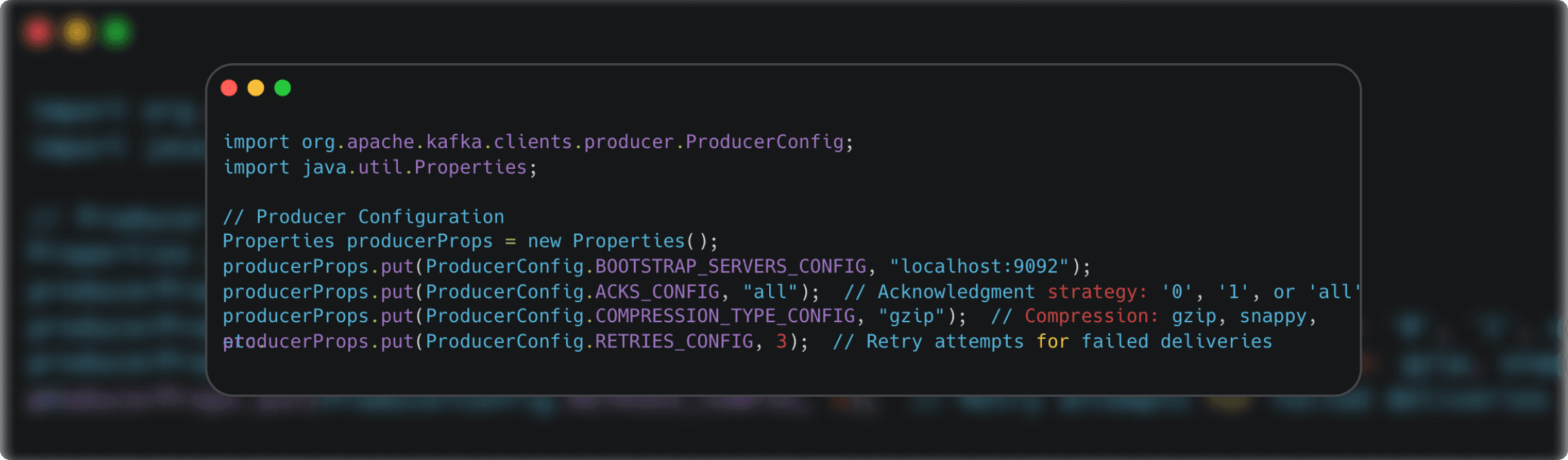
- acks: : Controls the acknowledgement strategy (0, 1, or a 11) for durability and speed.
- compression.type: : Enables compression algorithms (gzip, snappy, etc.) for bandwidth optimization.
- retries: : Specifies the number of retry attempts for failed message deliveries.
Consumer-side settings manage how messages are consumed and offsets are tracked for seamless data processing.
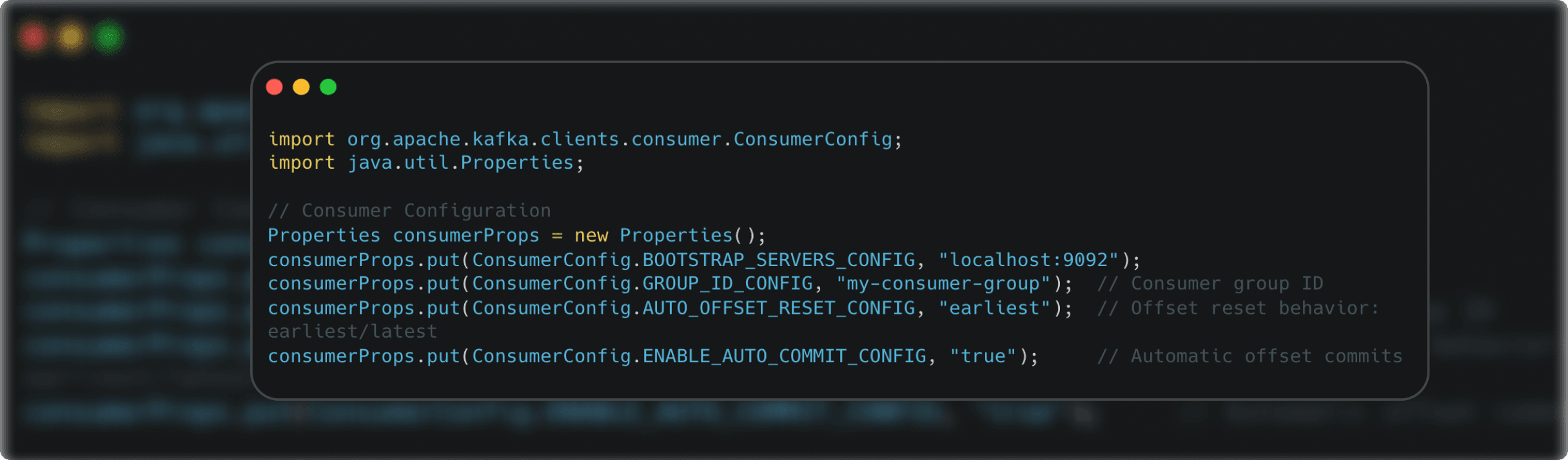
- group.id: : Identifies the consumer group for coordinated partition consumption.
- auto.offset.reset: : Determines offset behavior when there is no committed offset (earliest to start at the beginning, latest to pick up new messages).
- enable.auto.commit: : Automates offset commits to track consumer progress.
Apache Kafka has become the go-to solution for modern data workflows due to its ability to handle high-throughput, real-time data streaming with scalability and fault tolerance. Its distributed architecture allows seamless integration across various systems, making it ideal for event-driven applications, real-time analytics, and large-scale data pipelines.
Apache Kafka is designed to handle data as it happens, enabling businesses to act instantly on critical insights. This makes it invaluable for scenarios like fraud detection, live tracking, and delivering personalized user experiences. Its capability to stream data in real time ensures no delay in processing or decision-making.
Kafka’s architecture ensures that data producers and consumers operate independently, providing unmatched flexibility. This separation means you can upgrade, scale, or modify parts of the system without affecting the entire data pipeline, making Kafka ideal for dynamic and evolving business environments.
Kafka is engineered to manage enormous workloads, handling millions of events per second with ease. Its distributed design ensures data replication across multiple servers, offering high fault tolerance and uninterrupted performance even in case of system failures.
With its ability to integrate with almost any technology stack, Kafka acts as the backbone of a connected ecosystem. Whether you’re working with IoT devices, cloud platforms, databases, or analytics tools, Kafka bridges the gap, creating a streamlined flow of data across diverse systems.
Apache Kafka is a game-changer for real-time data streaming and event-driven architectures, but it’s not always the right fit. Choosing Kafka for unsuitable scenarios can lead to overengineering, wasted resources, and operational headaches. Let’s dive into situations where Kafka might not be your best option.
Kafka thrives in environments with high-velocity data streams, but if your use case involves small-scale or infrequent data events, Kafka can feel like using a sledgehammer to crack a nut. Setting up Kafka for low-data pipelines introduces unnecessary complexity.
Kafka’s distributed publish-subscribe model shines for broadcasting data to multiple consumers or aggregating from many producers. However, for direct, point-to-point messaging, Kafka’s distributed nature adds unnecessary overhead.
If your application requires microsecond-level latency, such as high-frequency trading or real-time gaming, Kafka may not deliver the instantaneous response you need. Its processing model focuses on throughput and fault tolerance over ultra-low-latency guarantees.
Kafka guarantees message ordering within partitions but doesn’t extend that guarantee across topics or partitions. For use cases requiring strict ordering across the entire system—like certain financial transactions—this limitation can be a dealbreaker.
Apache Kafka is the leading platform for real-time data streaming, providing unmatched scalability, fault tolerance, and flexibility for modern data workflows. It enables businesses to process high-volume data instantly, making it perfect for real-time analytics, event-driven architectures, and large-scale data integration. While Kafka excels in high-throughput environments, it may not be the best choice for low-data use cases or ultra-low-latency applications. Understanding when to use Kafka ensures optimal performance and cost efficiency. In today’s fast-paced, data-driven world, Kafka is essential for businesses looking to innovate and future-proof their data pipelines.
Your AI future starts now.
Partner with Radiansys to design, build, and scale AI solutions that create real business value.