
Mastering Apache Airflow: A Comprehensive Guide to Workflow Automation and Orchestration
January 24, 2025
Lovneet Singh
Sr. Architect @ RadiansysIntroduction
In today’s data-driven world, automation and orchestration are at the heart of efficient data pipelines, particularly when working with big data, machine learning, or ETL workflows. Apache Airflow is one of the leading open-source tools designed for precisely this purpose. In this guide, we will dive deep into Apache Airflow, exploring its features, how it works, and how to get started with it. Whether you're an experienced developer or just starting, this article will be a practical and detailed resource for mastering Airflow.
What is Apache Airflow?
Apache Airflow is a platform used to programmatically author, schedule, and monitor workflows. It is designed to handle complex computational workflows, data pipelines, and automation tasks. Airflow provides an intuitive user interface for managing workflows, as well as a robust API for integration with external systems.
Core features of Apache Airflow include
Dynamic Workflow Creation
Task Scheduling
Monitoring & Logging
Scalability
Why Use Apache Airflow?
Airflow has emerged as one of the most popular orchestration tools for data workflows. Here are a few reasons why:

Airflow allows users to define workflows as code. This gives you the freedom to use the tools, libraries, and systems that suit your needs best.

Airflow offers a powerful UI to monitor workflows in real time. You get clear visibility into task execution, retries, logs, and overall progress as your workflows run.

Airflow is feature-rich yet simple to work with. You can quickly start with basic workflows and scale as your requirements grow, making it beginner-friendly and flexible.

With its wide ecosystem of plugins and integrations, Airflow can easily connect with tools like Hadoop, Spark, AWS, and Google Cloud, giving you endless expansion options.

As an Apache open-source project, Airflow has a strong global community. You’ll find extensive documentation, resources, and plugins that help enhance and support your workflows.
Understanding How Apache Airflow Works
At its core, Apache Airflow manages workflows through a Directed Acyclic Graph (DAG). A DAG represents a collection of tasks and their dependencies, specifying the order in which they should be executed.
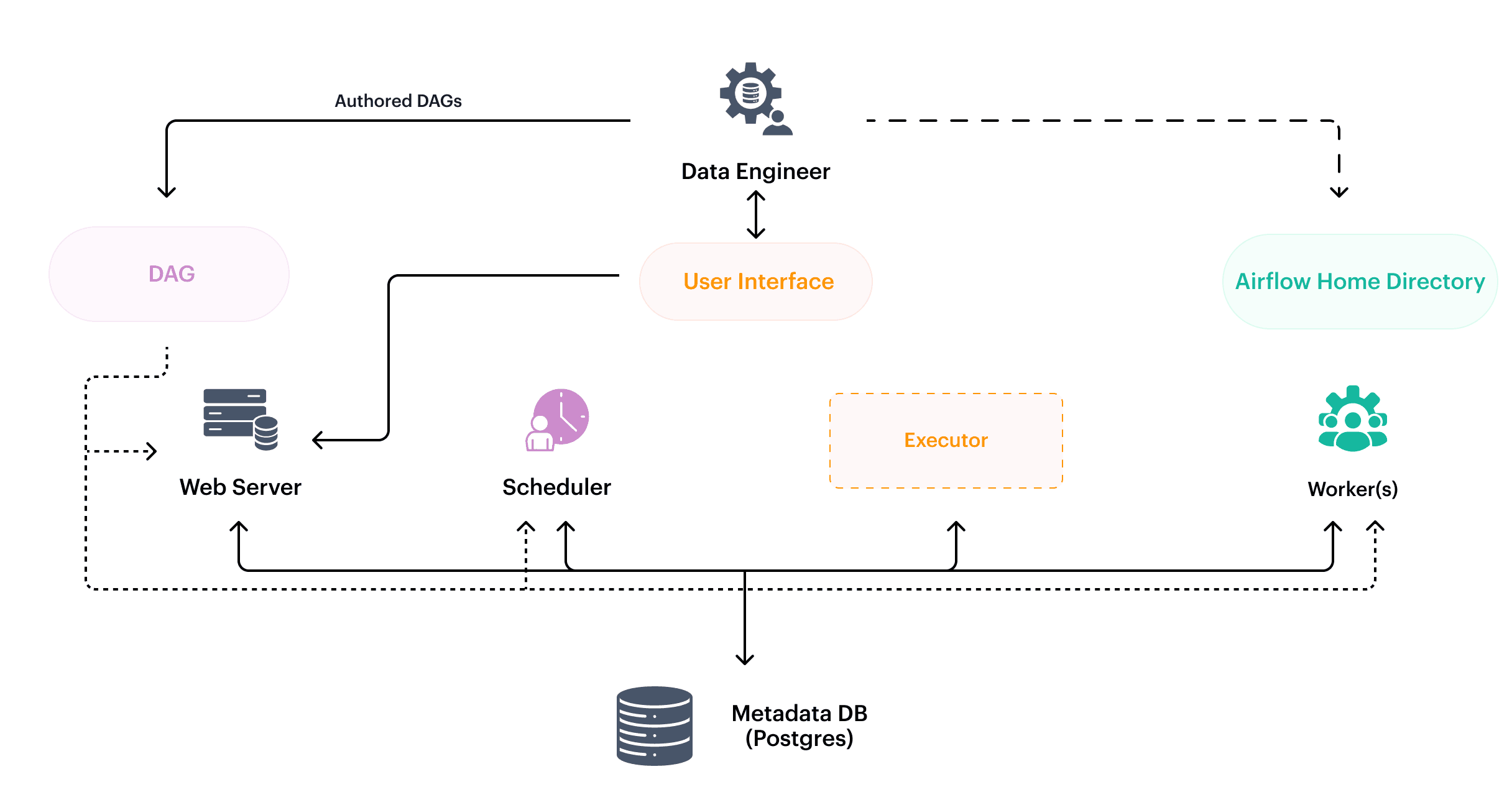
Key Components of Airflow
DAG (Directed Acyclic Graph): The structure that represents your workflow, where each node is a task and edges represent dependencies between tasks.
Task: A single unit of work within a DAG. Tasks are typically Python functions, Bash scripts, or operations on external systems.
Operator: Operators define how tasks are executed. They are predefined actions that represent a specific kind of work, such as running a Python script, sending an email, or executing a SQL query. Common operators include PythonOperator, BashOperator, PostgresOperator, etc.
Scheduler: The component responsible for running the tasks in the right order, based on the DAG's schedule and task dependencies.
Executor: Executes the tasks in the workflows. Airflow supports several executors such as SequentialExecutor, LocalExecutor, CeleryExecutor, and KubernetesExecutor, depending on your environment and scaling needs.
Web UI: Airflow comes with a powerful web interface that allows you to manage, monitor, and debug DAGs and tasks. You can see task status, logs, and more.
Airflow Database: Airflow uses a relational database to store metadata like DAG definitions, task statuses, execution logs, and other workflow-related data.
A Step-by-Step Guide for New Users
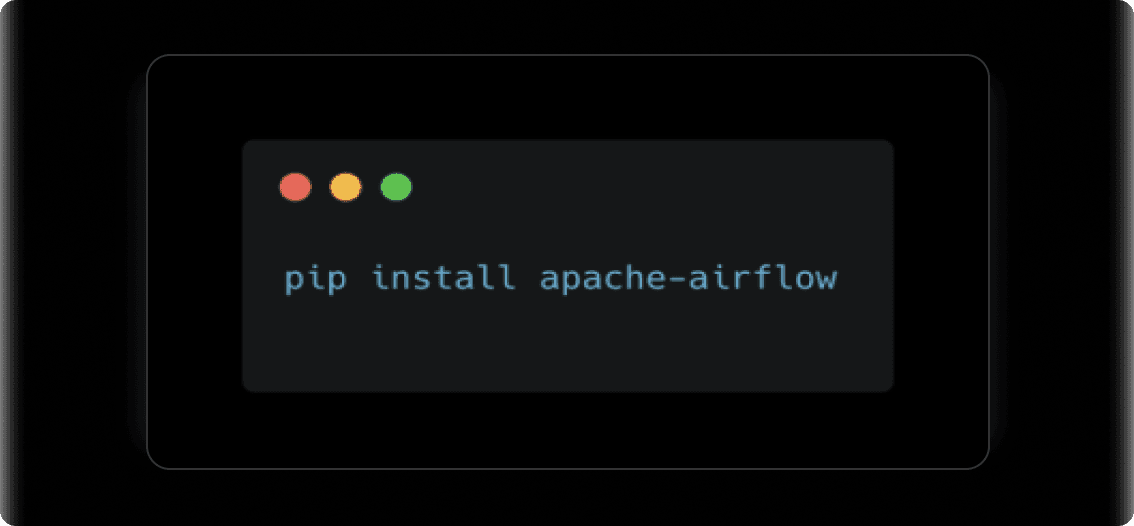
Install Apache Airflow
You can install Airflow using Python’s package manager pip.
1. Install Apache Airflow:
2. Initialize the Airflow Database:

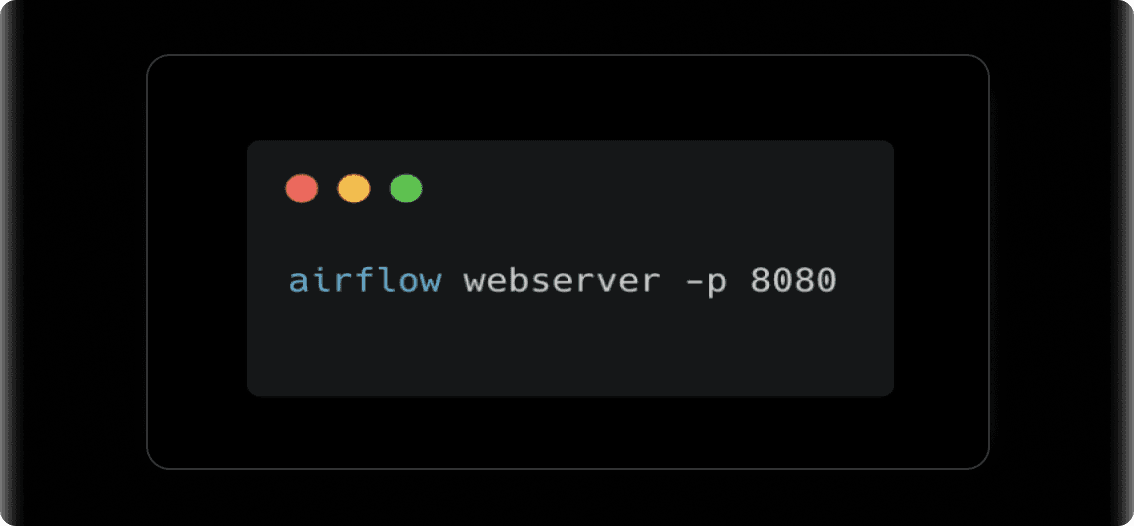
3. Start the Web Server:
4. Start the Scheduler

5. Access the Airflow UI: Open a browser and go to http://localhost:8080 to access the Airflow web UI.
Create Your First DAG
To create a workflow in Airflow, you need to define a DAG. A simple DAG can be created as follows:
1. Create a Python file for your DAG, for example, my_first_dag.py in the dags/ directory.
2. Define your DAG and tasks
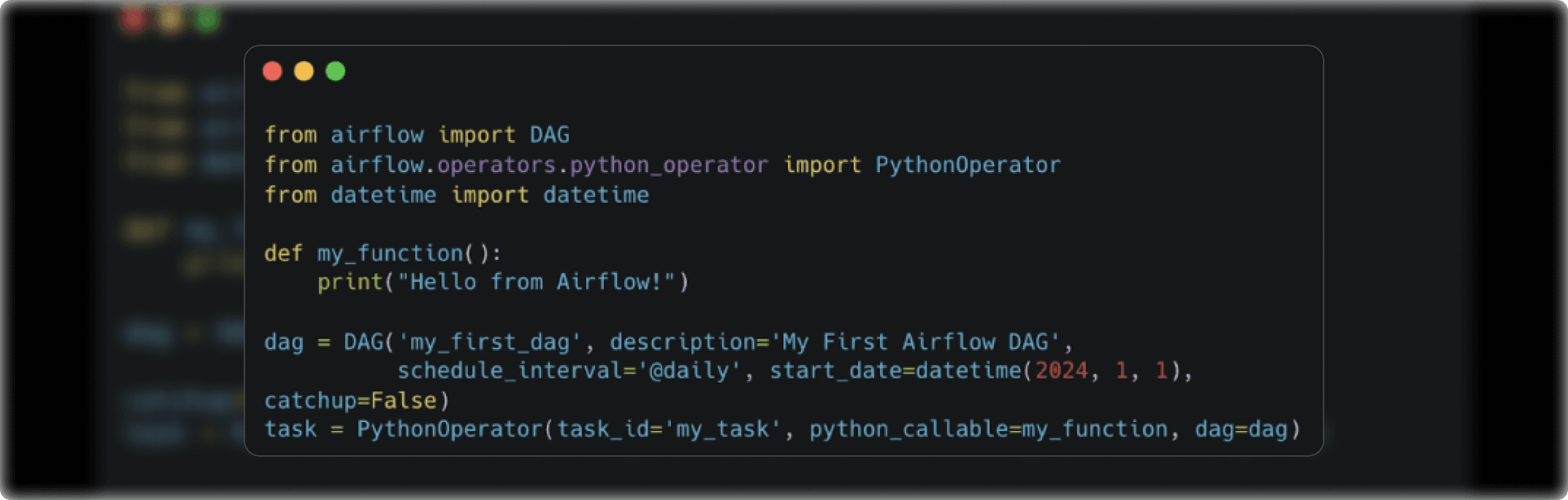
3. Once your DAG is defined, you can see it in the Airflow web UI under the DAGs tab. You can manually trigger it or let it run on its schedule.
Task Dependencies, Failures, and Event Triggers
To create powerful, resilient, and flexible workflows that meet the demands of modern data engineering and automation, one should know about task dependencies, failure handling, and external event triggers in Apache Airflow
A. What are Task Dependencies : Airflow's strength lies in its ability to define dependencies between tasks . within a Directed Acyclic Graph (DAG). These dependencies control the order in which tasks are executed, ensuring that certain tasks run only after others have been completed.
How to Set Task Dependencies
We can define task dependencies in Apache Airflow using different methods, with the two most common being the >> operator and the set_upstream() / set_downstream() methods.
1. Using the >> Operator: The >> operator is the most straightforward way to define task order. You use it to specify that one task should run after another.
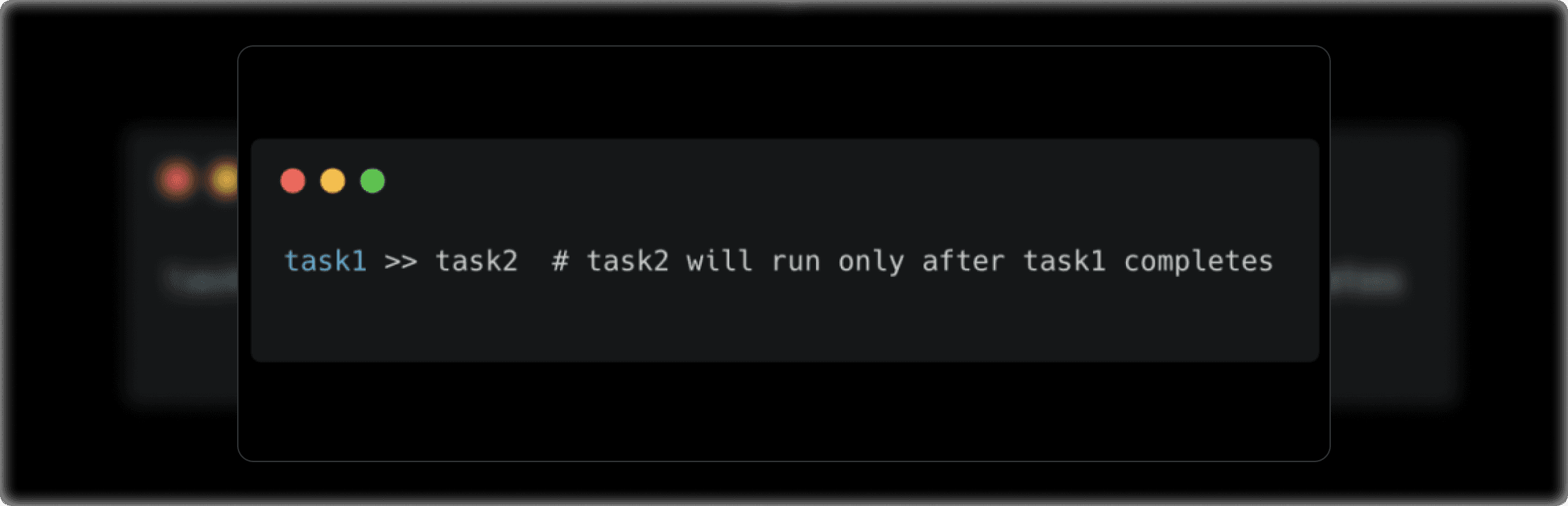
Here, task2 operator and is dependent on the successful completion of task1 . This approach makes your DAGs clean and readable.
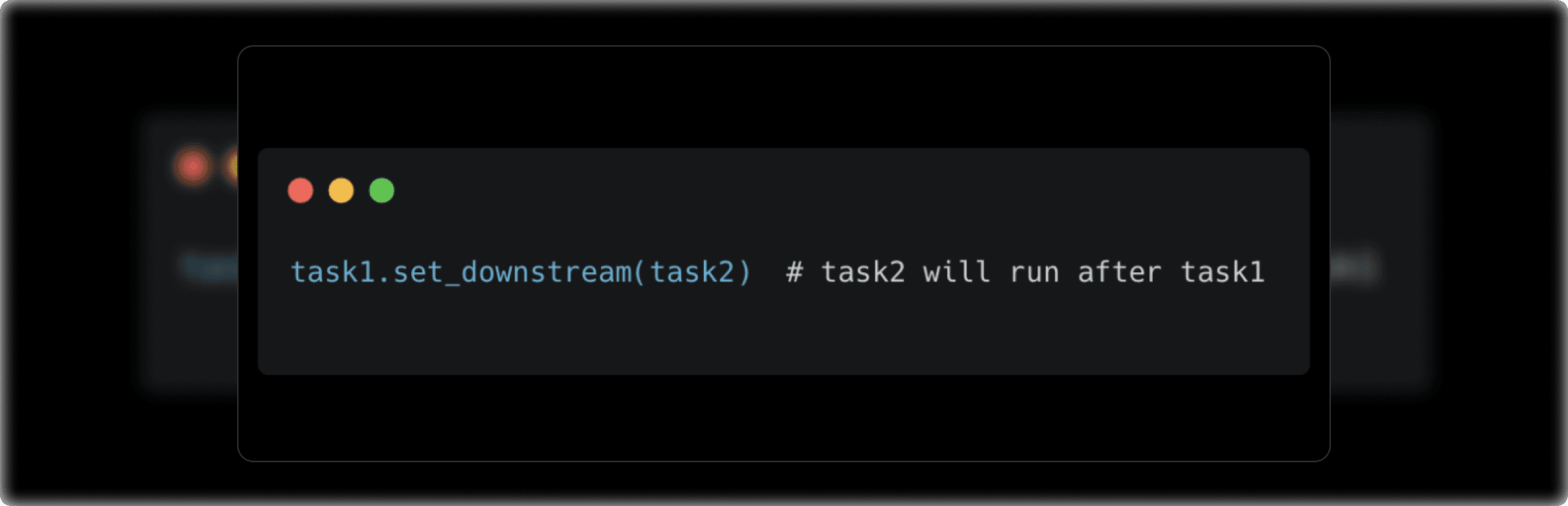
2. Using set_downstream() and set_upstream(): If you prefer a more programmatic way of defining dependencies, you can use set_downstream() and
- set_downstream() makes the current task the predecessor of the specified downstream task.
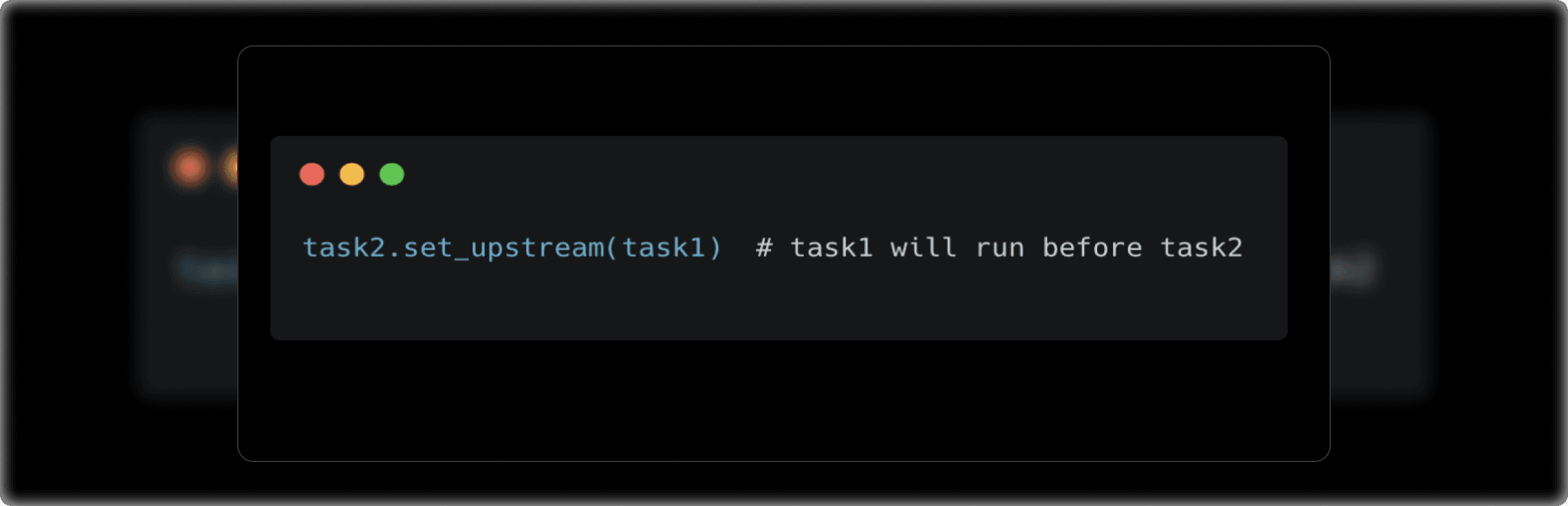
- set_upstream() does the opposite, making the current task the successor of the upstream task.
Or, you could use set_upstream() to reverse the order:
Complex Workflows
When we work with large, complex DAGs, organizing tasks into Task Groups or SubDAGs can make the workflows more readable and manageable.
- Task Groups: These allow us to group tasks together logically, making your DAGs cleaner and easier to navigate. Here's an example:
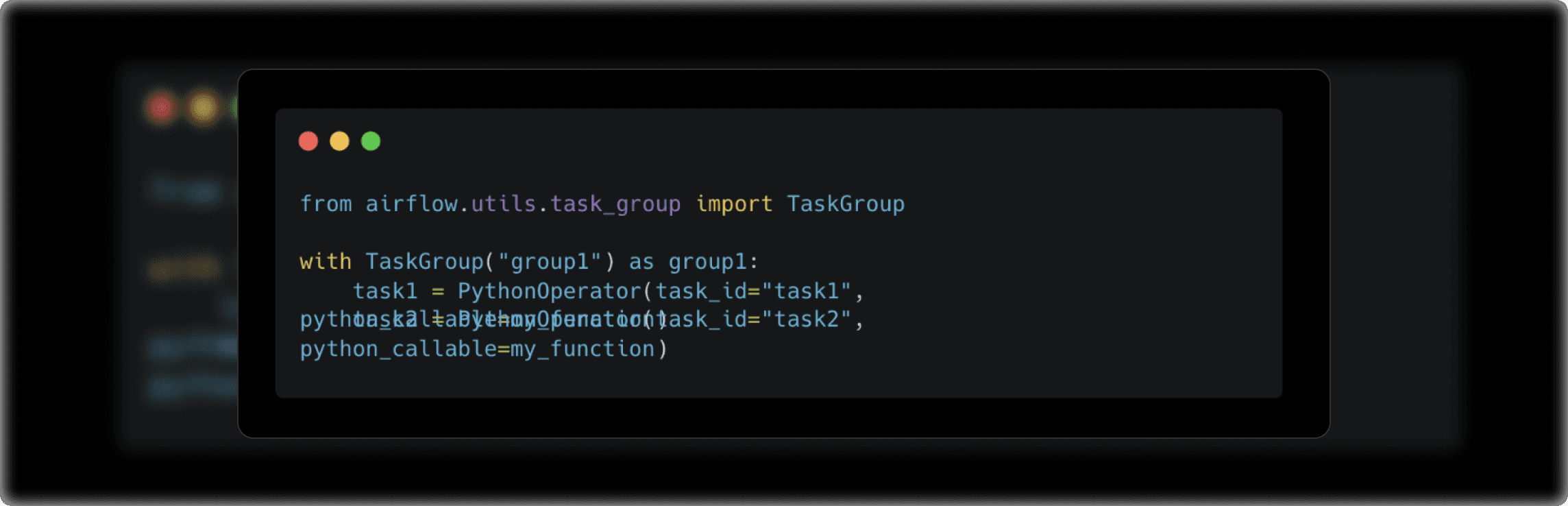
- SubDAGs: SubDAGs are essentially DAGs within a DAG. They allow us to encapsulate a set of tasks as an independent sub-workflow. This is useful when tasks within a specific section of your workflow are logically related but need to be separated for clarity.
B. Handling Failures and Retrying Tasks: To ensure the workflows are resilient even when tasks fail due to unexpected issues, Airflow provides several ways to manage task failures and retries.
Retry Mechanism
Intermittent failures, such as network issues or external system unavailability, can often be resolved by retrying the task. Airflow gives you control over how many times a task should be retried and how long to wait between retries.
Here’s how you can set up retries for a task:
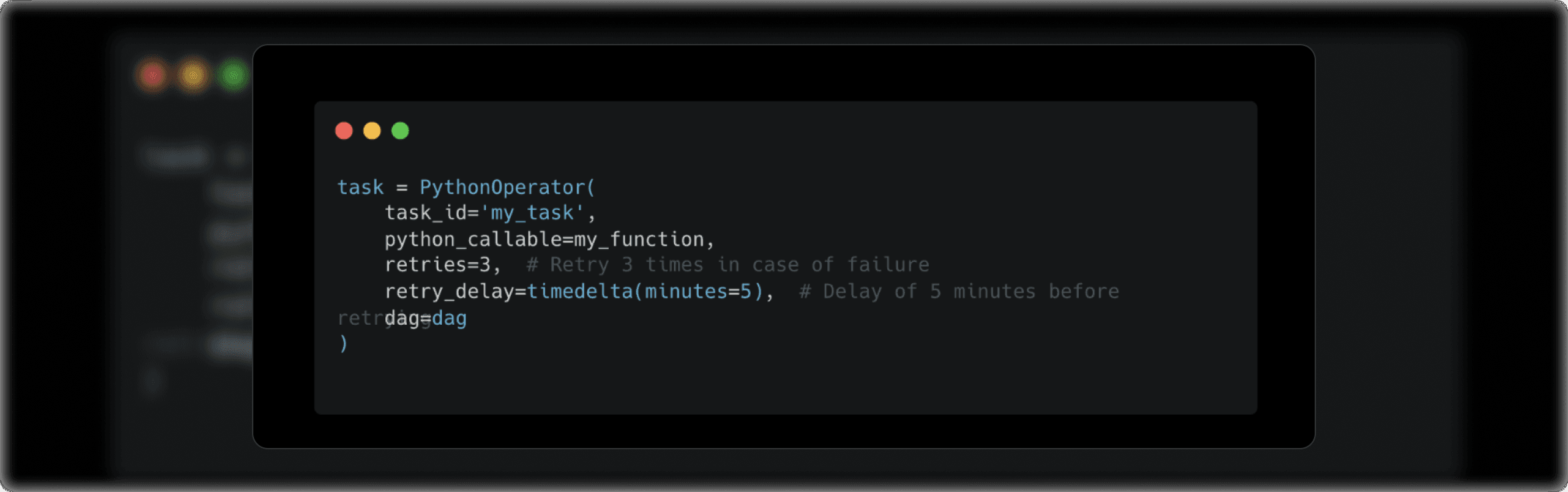
- retries: The number of retries that should be attempted before giving up on the task.
- retry_delay: The duration to wait before retrying the task.
Failure Callbacks for Custom Handling
In addition to retries, one might want to implement custom actions when a task fails. Airflow allows you to define failure callbacks—functions that are triggered when a task fails after exhausting its retries.
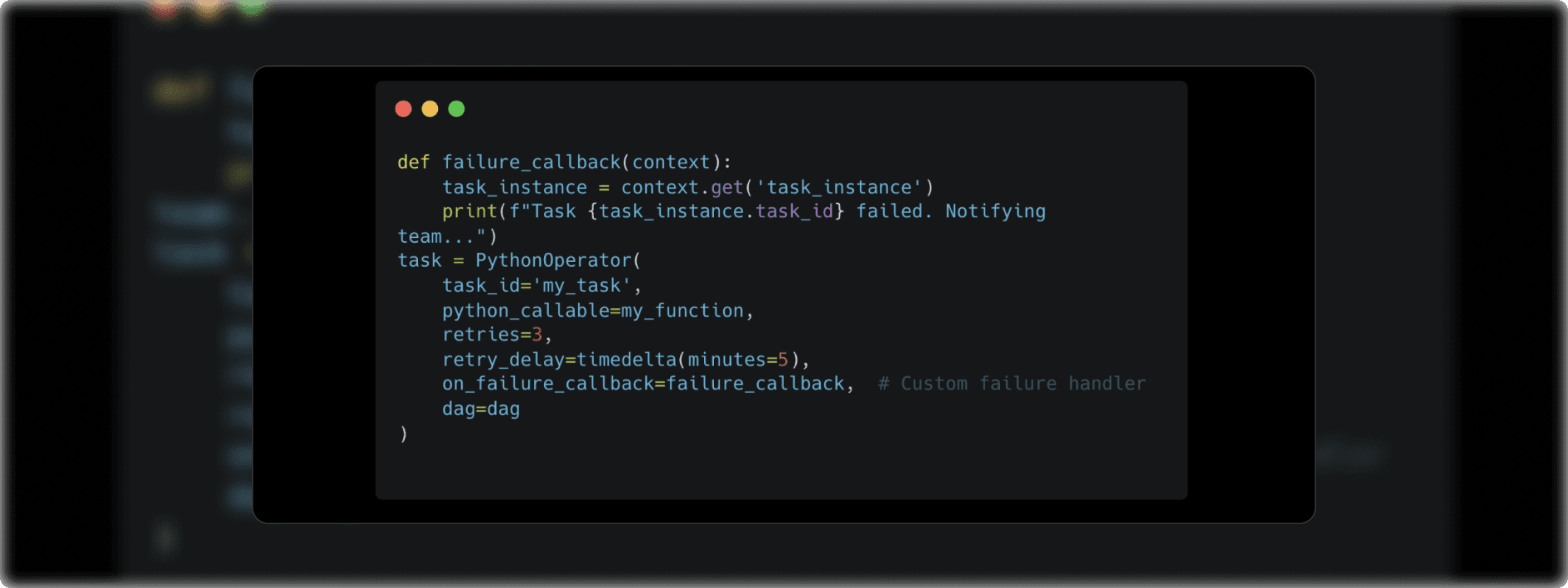
In this case, the failure_callback function will run whenever the task fails. You could use this for custom logging, alerting systems, or any other failure management process you deem necessary.
C. Triggering DAGs Based on External Events: Sometimes, you want to trigger workflows based on external events, such as the arrival of a file, an HTTP request, or the completion of another workflow. This adds flexibility to your workflows and makes them more event-driven.
Sensors: Wait for External Events
Airflow provides sensors to wait for certain conditions to be met before continuing with the execution of tasks. Common use cases for sensors include waiting for a file to arrive, an API to respond, or an external task to complete.
For example, the FileSensor waits for a file to appear in a specified path:
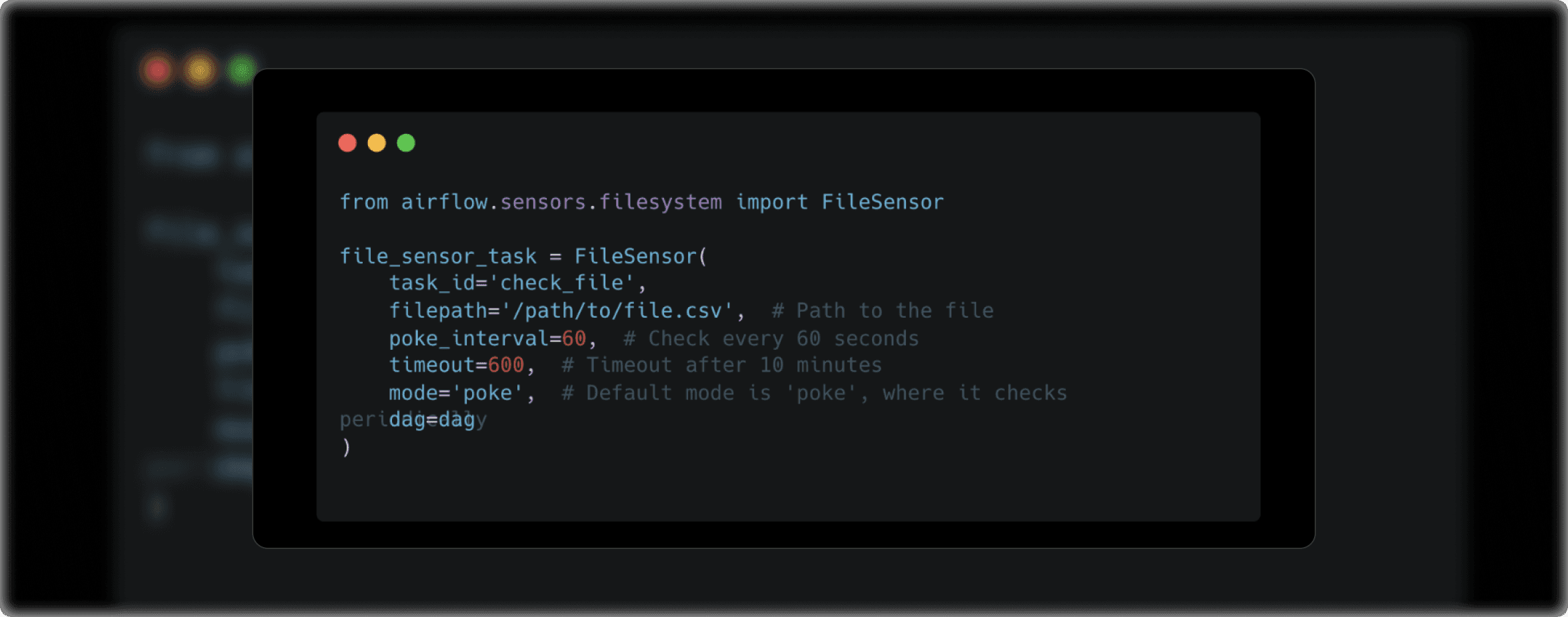
- poke_interval: The frequency (in seconds) with which Airflow will check for the file.
- timeout: The maximum duration (in seconds) the sensor will wait before giving up.
- mode: Determines how the sensor behaves. In poke mode, it periodically checks for the condition. In reschedule mode, tasks are paused and rescheduled to avoid constant polling.
Triggering DAGs from External Systems
Sometimes you may need to trigger a DAG manually or from an external event like a webhook, REST API, or message queue. Airflow supports this through its API and other triggers.
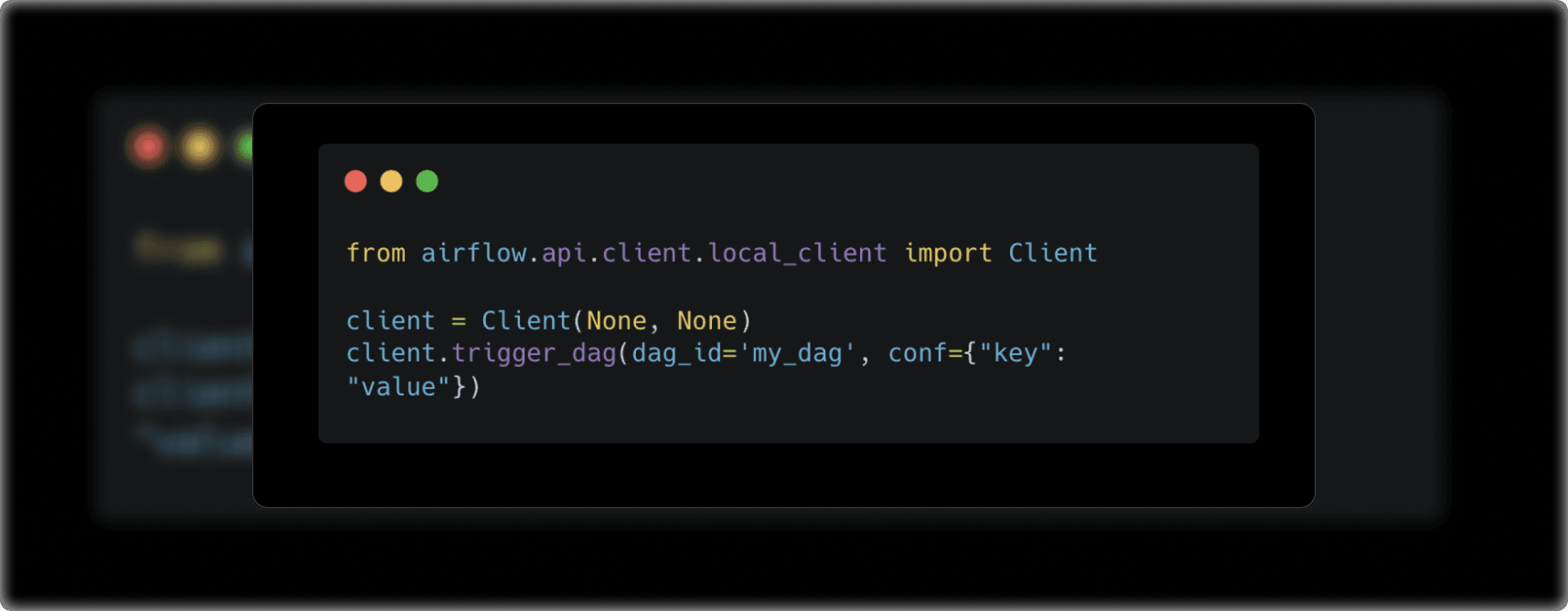
This allows you to trigger DAGs programmatically, which is useful for integrating Airflow with other systems, such as CI/CD pipelines or external event-driven platforms.
Best Practices for Apache Airflow
Modularize your DAGs
Keep your DAGs small and modular. Create reusable components and use Airflow’s extensive libraries to avoid code duplication.
Use Virtual Environments
Ensure that each project runs in a dedicated virtual environment to avoid dependency issues.
Handle Failures Gracefully
Set retries, timeout, and alert mechanisms to ensure workflows continue smoothly even if tasks fail.
Monitor Performance
Use Airflow's built-in tools to monitor task execution times, dependencies, and failures. Ensure that DAGs do not become too large or complex.
Use Version Control
Store your DAGs and associated files in version control systems like Git to manage changes effectively.
Integrating Apache Airflow with Other Tools
One of the main advantages of Airflow is its extensibility. You can integrate it with a wide variety of tools such as
Apache Spark for big data processing
AWS for cloud-based workflows
Google Cloud for managing cloud-native applications
Databases for ETL workflows
For example, you can trigger an Airflow task that runs a Spark job on an AWS EMR cluster.
Conclusion
Apache Airflow is a powerful and flexible tool for orchestrating complex workflows. Its ability to handle large-scale automation, combined with easy-to-use interfaces and integrations, makes it a favorite among data engineers and developers. Whether you are building an ETL pipeline, managing cloud resources, or automating machine learning workflows, Apache Airflow provides the tools you need for efficient, reliable task orchestration.
Thanks for reading!
Your AI future starts now.
Partner with Radiansys to design, build, and scale AI solutions that create real business value.